Plenty of text data are freely available from the web, but importing them in a text analysis system can be somewhat tedious. In this post, we’ll use Textable to automate most of the process of building a corpus of theatre plays retrieved from the internet.
The Théâtre Classique website offers more than 800 French plays in TEI/XML format. Out of these, we’ll collect all the plays from two specific authors, Jean Racine and Pierre Corneille.
The first step is to identify the URLs of the texts that we’re interested in. In this particular case, our task is made more complicated by the fact that there are no direct links to the XML files on the target website’s table of contents. However, we do see in the source code of that page a number of references to XML files:

Some experience and experimentation makes it possible to determine that the actual URLs of the desired files all result from concatenating a base path (http://www.theatre-classique.fr/pages) with what follows edition.php?t=.. in the previous screen capture:
http://www.theatre-classique.fr/pages/documents/RACINE_ALEXANDRE.xml http://www.theatre-classique.fr/pages/documents/RACINE_ALEXANDRE66.xml ...
Having determined the piece of information that we need to retrieve in the first place, we may start using Textable to that effect. First, we’ll create an instance of the URLs widget and configure it to import the HTML source of the website’s table of contents:

Next, we’ll create an instance of Segment and use to extract the partial URLs of each author’s plays:
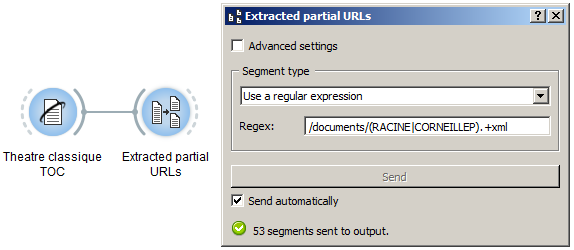
The regular expression in the previous screenshot is meant to retrieve every substring that begins with /documents/ and either RACINE or CORNEILLEP, and that ends with .xml (P is used to distinguish between Pierre and Thomas Corneille).
The next step is to take each partial URL previously extracted and convert it into a complete URL. Each resulting URL must then be integrated in a fragment of JSON code, that will later be used to configure automatically a new instance of the URLs widget. This widget will eventually download the desired XML files.
The JSON data that is expected by the URLs widget looks like this (see Textable documentation):
[ { "url": "http://www.theatre-classique.fr/pages/documents/RACINE_ALEXANDRE.xml", "encoding": "utf-8" }, { "url": "http://www.theatre-classique.fr/pages/documents/RACINE_ALEXANDRE66.xml", "encoding": "utf-8" }, [many more such entries...] ]
In a nutshell, the format can be described like this:
With this by way of background, we may use the advanced settings of the Display widget to generate the needed JSON data on the basis of the extracted URLs:
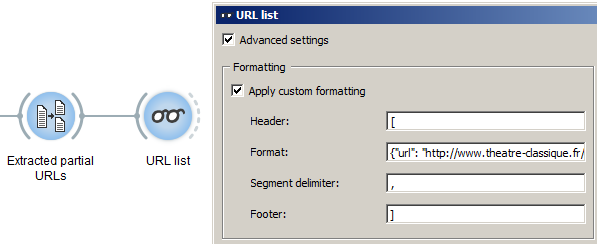
Configuring the Header, Segment delimiter, and Footer fields is fairly straightforward. Specifying the right Format is more challenging, because it requires using a special notation for the variable part of the output: the predefined %(__content__)s code, which in this case represents the partial URLs:
{
"url": "http://www.theatre-classique.fr/pages%(__content__)s",
"encoding": "utf-8"
}
NB: spacing (blanks, carriage returns) is irrelevant; in practice it’s easier to just ignore it and type all the format in a single line.
There’s only one more thing to do at this point: convert the JSON data that we’ve just generated into an object that can be fed to the URLs widget. To do that, we’ll simply connect Display with a new instance of Message, then right-click on the connection, and select Reset Signals:
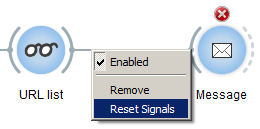
In the dialog that opens, we’ll replace the default connection, which originates from the Bypassed segmentation channel, by a new one that originates from Displayed segmentation (which corresponds to the JSON data generated in the previous step).

We can finally connect Message with a new instance of URLs, and after a short time devoted to actually dowloading the data, we find ourselves looking at 53 XML files totalling 8 millions characters and ready to be further analyzed with Textable, which we’ll do in another post.
